DeepSeek-OCR innovates Long-Context Compression
DeepSeek-OCR: Contexts Optical Compression
记得25年上半年在雁栖湖校区读书的时候看了B站up主EZConder讲了DeeoSeek-V3和R1的系列视频,Top-Down的授课方式给我留下了很深的印象。EZ老师在视频里强调,知识就像是水流一样,后面他基于这种“水流”的思想把DeepSeek发展的来龙去脉很快就梳理出来了,非常值得学习的方式。
昨天DeepSeek团队推出了新的模型:DeepSeek-OCR,一经发布便火遍全网,也正值自己前一阵子在关注Prompt Compression与Long Contexts Compression的相关内容,所以也想以这种“水流”的思想把论文串一下。Good idea的出现绝非偶然,不仅要关注当前这篇文章的创新点,同时也要关注当前的这篇文章前期工作有什么,思路是从哪些文章延伸过来的,以及基于现有知识可以做出哪些创新。
上下文压缩时间线
第一部分将 DeepSeek-OCR 的“光学压缩”思想放入上下文压缩技术发展的时间线中,清晰地构建出一条从“处理”长上下文到“压缩”长上下文的演进脉络。
Stage1:RAG早期
这个阶段的核心思想是“不直接让LLM处理全部的上下文,而是在输入前进行筛选和精简”。
本阶段的核心问题是:LLM上下文窗口有限且处理成本昂贵。
解决方案:
- 后检索过滤,通过计算查询与检索文档的向量相似度,丢弃掉不那么相关的文档。[EmbeddingsFilter]
- 后检索摘要,通过计算查询(Query)与检索文档的向量相似度,丢弃掉不那么相关的文档。[LLMChainExtractor]
Stage2:提示工作与蒸馏
这个阶段的核心思想是不改变LLM架构,而是学习一种更为精简的的‘soft prompt’来代替冗长的原始上下文。
核心问题:如何让压缩后的信息能被LLM高效理解。
解决方案:将长上下文“蒸馏”成密集向量的形式。
- 通过训练,让模型学会将长指令或上下文的“要点”(gist)压缩到几个特殊的 gist tokens 中。[Gist]
- 训练一个小型模型,专门用来识别并删除原始提示中的“不重要”词元(tokens),同时保证压缩后的提示能让 LLM 做出同样的回答。[LLMLingua系列]
Stage3:专有压缩器与自编码器
这个阶段的核心思想是构建一个独立于特定任务、可学习的压缩器,将任意长上下文编码为固定长度的向量表示,是的压缩上下文成为一个通用的、可插拔式的模块组件。
核心问题:如何实现一种高效且通用的上下文压缩方法?
解决方案:引入自编码器思想,训练一个 Encoder 将长文本压缩成一组“记忆向量”,然后要求一个 Decoder(通常是固定的 LLM)能够基于这些向量完美地重构原文。[ICAE]
Stage4:提升压缩效率与可扩展性
这一阶段的核心思想是在保证压缩质量的同时,将压缩过程的效率推向极致,并解决超长序列的训练难题。
核心问题:上一阶段的压缩器虽然有效,但压缩本身还是太慢,并且难以在真正超长的文本上进行训练。
解决方案:优化压缩器架构和训练策略。
- 压缩器的瓶颈在于自注意力机制,创新性地仅使用交叉注意力。让一小组可学习的“摘要词元”作为Query,去原文中提取信息。直接将压缩的复杂度从O(n²) 降到了**线性复杂度 O(n)**。[In-Context Former]
- 使用分块处理和优化采样策略是的模型在极长的序列上进行训练而不会爆显存,将压缩结果直接注入到LLM的KV-Cache使得可扩展性得以提高。[CCF]
OCR长文档处理
多模态大语言模型处理长上下文是面临的挑战:计算成本巨大、视觉编码效率低下、长文本采样受限。
Vision Transformer(ViT)模型通常需要将图像调整为固定分辨率,会丢失原始图像的长宽比信息,对于非方形的图像(如图表或文档)尤其次优。
处理文档级的高密度文本场景时,CLIP-style的视觉词汇表难以高效地将所有视觉信息编码到固定数量的Token中,容易导致信息损失。
| 阶段 | 核心论文 | 核心思想/技术 | 解决的局限性 |
|---|---|---|---|
| 视觉词汇表扩展 | Vary | 扩展视觉词汇表(Scaling up the Vision Vocabulary):提出Vary,为LVLMs增加新的、针对文档和图表等人工图像(Artificial Images)的视觉词汇表。使用自回归(Autoregression)方法训练新的视觉编码器(基于SAM-ViTDet)。 | 解决了CLIP-ViT在处理高分辨率、非英文OCR、文档/图表理解等特殊场景时出现的“视觉词汇表不足(Vision Out-of-Vocabulary)”问题。 |
| 精细化焦点与长上下 | Fox | 聚焦任意位置(Focus Anywhere):提出Fox,通过位置感知提示(Position-aware Prompts)(如点、颜色、方框)来实现细粒度的文档理解,如区域OCR/翻译/总结。并扩展到多页面文档。 | 实现了对文档内容的细粒度交互(类似于“阅读笔”功能),并且在保持高压缩比的同时,支持了跨页面的上下文理解。 |
| DeepSeek-OCR:核心思路的最终体现 | DeepSeek-OCR | 上下文光学压缩(Contexts Optical Compression):将文本处理为图像,使用DeepEncoder(包含窗口注意力、卷积压缩、全局注意力)高效地将图像Token压缩到极少量,然后由MoE解码器解码。 | 实现了极高压缩比(如10倍压缩率)和高解码精度(如97%),从而根本上解决了大模型处理长上下文的计算瓶颈。 |
DeepSeek-OCR
设计思想
核心思想:探索一种全新的长上下文压缩方法,即上下文光学压缩(Contexts Optical Compression)。传统的大语言模型(LLMs)在处理长文本时,会因为序列长度的增加而面临巨大的计算挑战。
实现思路:利用视觉模态作为文本信息的高效压缩媒介。将文本内容渲染成图片,然后利用视觉模型(VLM)来处理这张图片。由于一张图片可以用远少于等效数字文本的vision tokens来表示,因此可以实现极高的信息压缩率。
架构细节
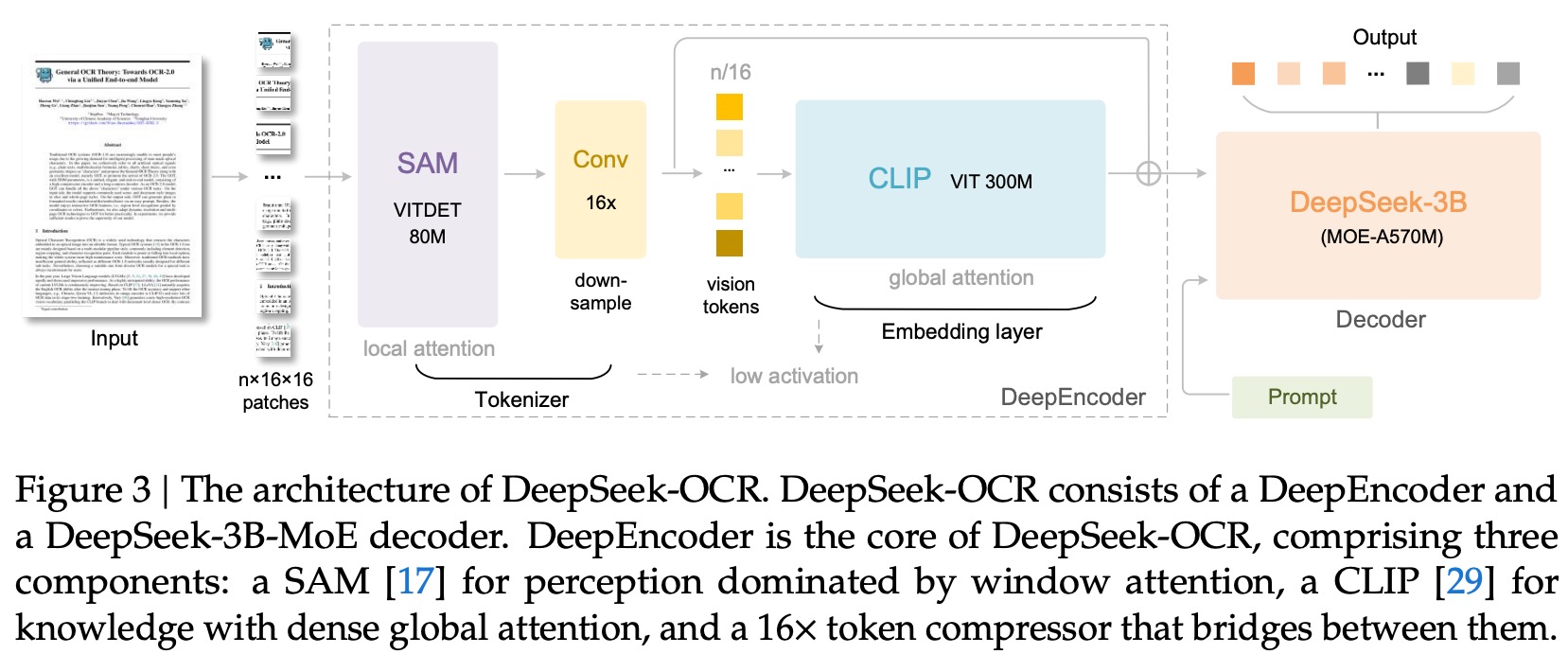
编码器:DeepEncoder:负责从输入图像中提取特征、进行标记化(tokenizing)并压缩视觉表示。
组成:
- **感知部分 (SAM)**:采用一个8000万参数的SAM(Segment Anything Model)模型,它以窗口注意力(window attention)为主,负责处理高分辨率图像的局部感知特征。
- **16倍卷积压缩器 (Conv 16x)**:在感知部分和知识部分之间,使用一个双层卷积模块,对视觉Token进行16倍的降采样。这极大地减少了进入后续全局注意力模块的Token数量,从而有效控制了计算量和内存占用。
- **知识部分 (CLIP)**:采用一个3亿参数的CLIP模型,它以密集的全局注意力为主,负责提取图像的全局知识性特征。
解码器:DeepSeek-3B-MoE Decoder:解码器采用了DeepSeek-3B-MoE模型,这是一个拥有30亿参数但激活参数仅为5.7亿的混合专家(Mixture-of-Experts)模型。它的作用是接收由DeepEncoder生成的、被高度压缩的视觉Tokens,并根据用户的prompt生成最终的文本结果。