沐神论文阅读速览
2025年4月15日,星期二,晴天☀️,第58篇博客。
这篇Blog耗时长,花费了很大精力和心血,但是感觉一切都值得、有价值!
跟着李沐读经典论文
今天听了大老师讲文献阅读课后很受启发,主要讲了文献阅读的方法以及如何找idea。
WWH → IDEA
- why:为什么要做这个研究?
- what:研究发现了什么?
- how:研究时如何实施的,用了什么方法?
明确科研目的 - 结果导向 以终为始
看文献,找方向
定方向,找创新
遇难题,找方法
始动笔,找支撑
跟进展,保状态
对于motivation的描述一定要多下功夫,核心就是要让论文在逻辑上要形成闭环。
六月中下旬就要离开雁栖湖了,离湖之前,跟着李沐老师把人工智能领域的经典文章再读一遍。
经典论文阅读
用WWH方法去分析每篇文章的核心思想,总结好模型结构图,每篇经典文章使用一句话总结说明
- ImageNet Classification with Deep Convolutional Neural Networks(NIPS 2012);https://proceedings.neurips.cc/paper_files/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf ; 作者:{Alex Krizhevsky、 Ilya Sutskever、Geoffrey E. Hinton}@University of Toronto;引用次数:142220;
首次提出使用卷积神经网络处理图像特征,完成图像分类任务,极大提升了图像识别的准确性。
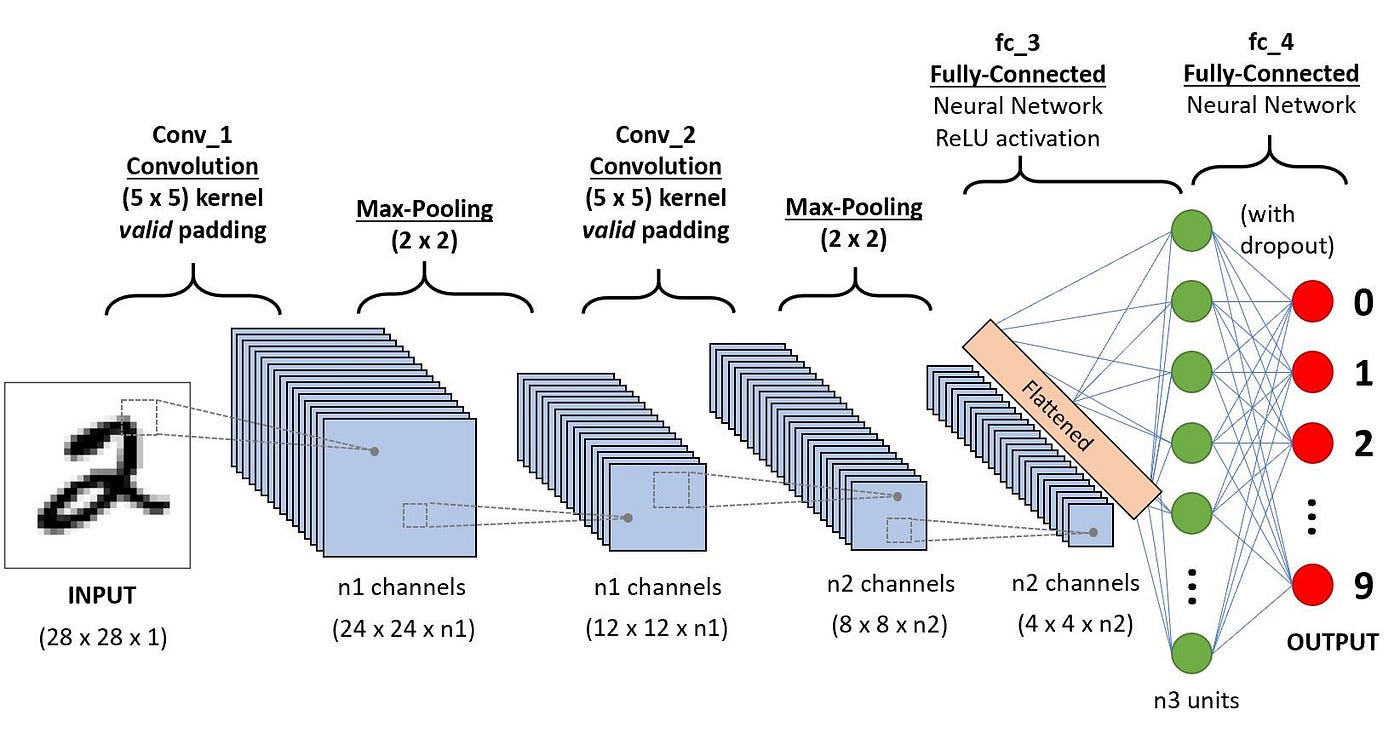
卷积操作一般都是使用卷积核在图片上扫描提取特征,使用ReLU函数作为激活函数,引入DropOut技术减轻过拟合,并在GPU上进行并行计算。
- Deep Residual Learning for Image Recognition(CVPR 2016); https://arxiv.org/pdf/1512.03385; 作者:{Kaiming He、 Xiangyu Zhang、Shaoqing Ren、 Jian Sun}@Microsoft Research;引用次数:264384;
论文首次引入了残差学习块(Residual Block),拟合目标变为输出y与输入x之间的“差值”:H(x) = ReLU(F(x) + x)。设计的初衷是让网络能够轻松的选择“跳过”某些层,从而使得训练深层网络成为可能。

残差块的设计实现是为了避免梯度反向传播的过程中发生消失的致命隐患。通过让快捷连接成为网络的基本组成部分,我们从结构上保证了梯度始终有一条“高速公路”可以回传到浅层,从而系统性地、主动地避免了梯度消失问题,使得设计者不必担心网络因深度增加而无法训练。
- Attention Is All You Need(NIPS 2017);https://arxiv.org/pdf/1706.03762; 作者:{Ashish Vaswanir、Noam Shazeer、Niki Parmar、Jakob Uszkoreit、Llion Jones、Aidan N. Gomez、Łukasz Kaiser、Illia Polosukhin}@Google Brain&Google Research&University of Toronto;引用次数:175945;
文章首次提出了Transformer架构,完全使用注意力机制代替之前基于CNN或RNN的编码解码解码模式,在机器翻译任务上性能得到了提升。

Transformer架构的核心组件:位置编码、前馈神经网络层、LayerNorm归一化层、self-Attn层(MultiHead Attn)、Cross-Attn层(Masked MultiHead Attn)。
参考博客:Attention Is All You Need
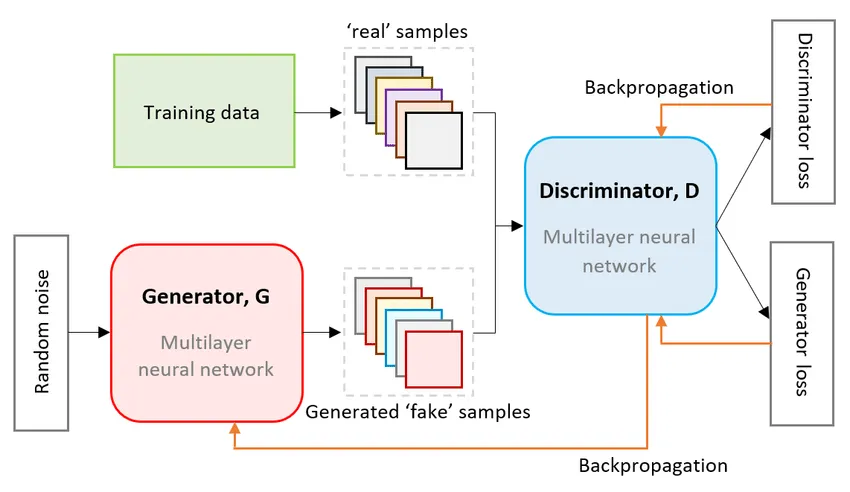
- Generative Adversarial Networks(NIPS 2014);https://arxiv.org/abs/1406.2661; 作者:{Ian J. Goodfellow、Jean Pouget-Abadie、, Mehdi Mirza、Bing Xu、David Warde-Farley、Sherjil Ozair、Aaron Courville、Yoshua Bengio}@Departement d’informatique et de recherche op ´ erationnelle&Universite de Montr ´eal&Montreal, QC H3C 3J7;引用次数:80508;
GAN网络设计的核心思想是设计俩个角色进行博弈:生成器 (Generator, G) VS 判别器 (Discriminator, D)。放弃了传统生成模型中复杂的概率密度计算,而是巧妙地将“生成”问题转化为了一个“判别”问题。通过设置一个动态的、不断变强的“对手”(判别器),来引导“自己”(生成器)不断进步。
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding(ACL 2019);https://arxiv.org/pdf/1810.04805; 作者:{jacobdevlin,mingweichang,kentonl,kristout}@google.com;引用次数:128516;
BERT的核心架构是Transformer的Encoder,使用Masked方式(完形填空)训练模型以具备序列生成的能力。
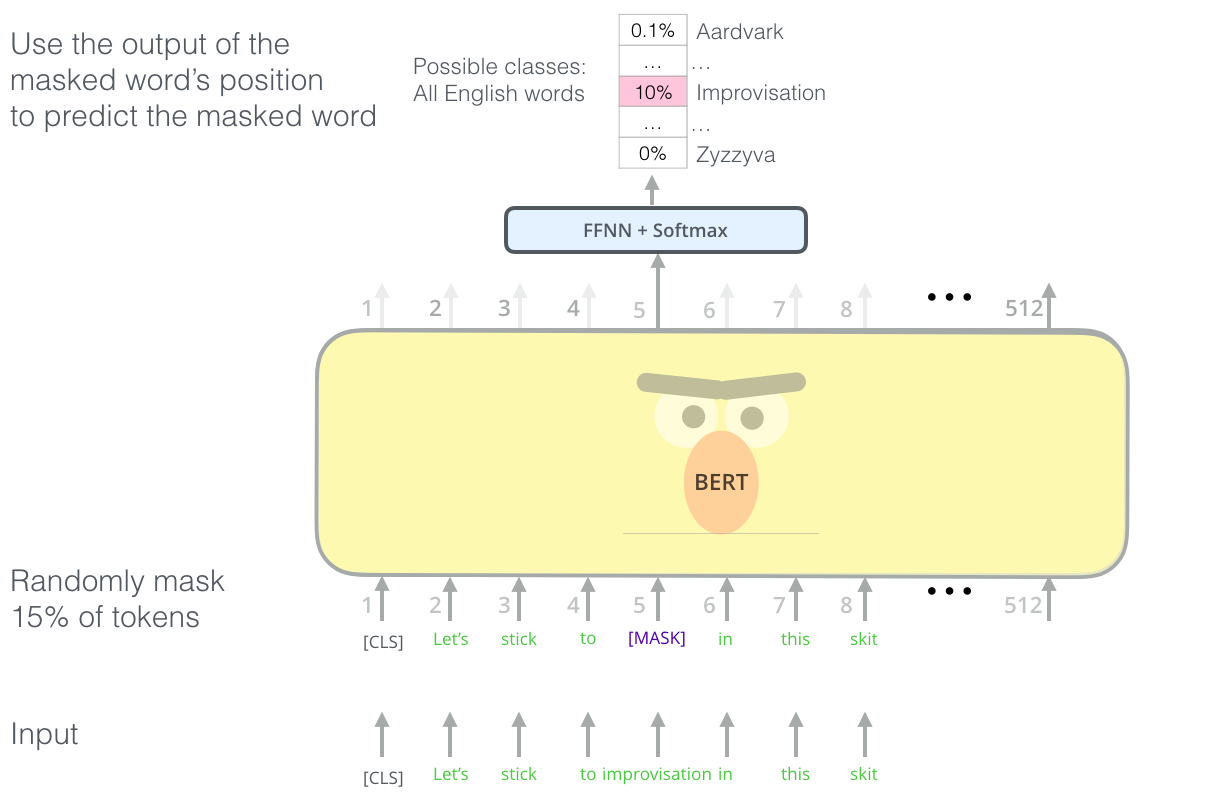
适用的下游任务:文本分类、情感分析、命名实体识别、回答
参考博客:动手学BERT
- Improving Language Understanding by Generative Pre-Training(OPENAI GPT);https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf; 作者:{Alec Radford、Karthik Narasimhan、Tim Salimans、Ilya Sutskever}@openai.com;引用次数:12611;
参考博客:动手学GPT
- Language Models are Unsupervised Multitask Learners(OPENAI GPT-2);https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf; 作者:{Alec Radford、Jeffrey Wu、Rewon Child、David Luan、Dario Amodei、Ilya Sutskever}@openai.com;引用次数:15577;
参考博客:动手学GPT
- Language Models are Few-Shot Learners(NIPS 2020/OPENAI GPT-3);https://arxiv.org/pdf/2005.14165; 作者:{Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, Dario Amodei}@openai.com;引用次数:43857;
参考博客:动手学GPT
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE(ICLR 2021);https://openreview.net/pdf?id=YicbFdNTTy 作者:{Alexey Dosovitskiy、Lucas Beyer、Alexander Kolesnikov、Dirk Weissenborn、Xiaohua Zhai、Thomas Unterthiner、Mostafa Dehghani、Matthias Minderer、Georg Heigold、Sylvain Gelly、Jakob Uszkoreit、Neil Houlsby}@Google Research&equal advising;引用次数:59885;
Masked Autoencoders Are Scalable Vision Learners(CVPR 2022);https://arxiv.org/pdf/2111.06377; 作者:{Kaiming He、Xinlei Chen、Saining Xie、Yanghao Li、Piotr Dollar、Ross Girshick}@Facebook AI Research (FAIR);引用次数:9490;
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows(CVPR 2021);https://arxiv.org/pdf/2103.14030; 作者:{Ze Liu、Yutong Lin、Yue Cao、Han Hu、Yixuan Wei、 Zheng Zhang 、Stephen Lin、Baining Guo}@microsoft.com;引用次数:29432;

- Learning Transferable Visual Models From Natural Language Supervision(PMLR 2021);https://arxiv.org/pdf/2103.00020; 作者:{Alec Radford、Jong Wook Kim、Chris Hallacy、Aditya Ramesh、Gabriel Goh、Sandhini Agarwal、 Girish Sastry、Amanda Askell、Pamela Mishkin、Jack Clark、Gretchen Krueger、Ilya Sutskever}@OpenAI;引用次数:29432;